了解es搜索过程中的相关性计算原理,对判断当前应用场景是否适合使用es来召回相关结果至关重要。本篇博文尝试对es在每一个节点执行搜索时如何计算query和经由倒排索引查询到的对应字段文本之间的相关性做简要说明。
ES搜索过程(节点层面)
ES的搜索过程具体到每一个节点可以简单地描述为三个步骤:
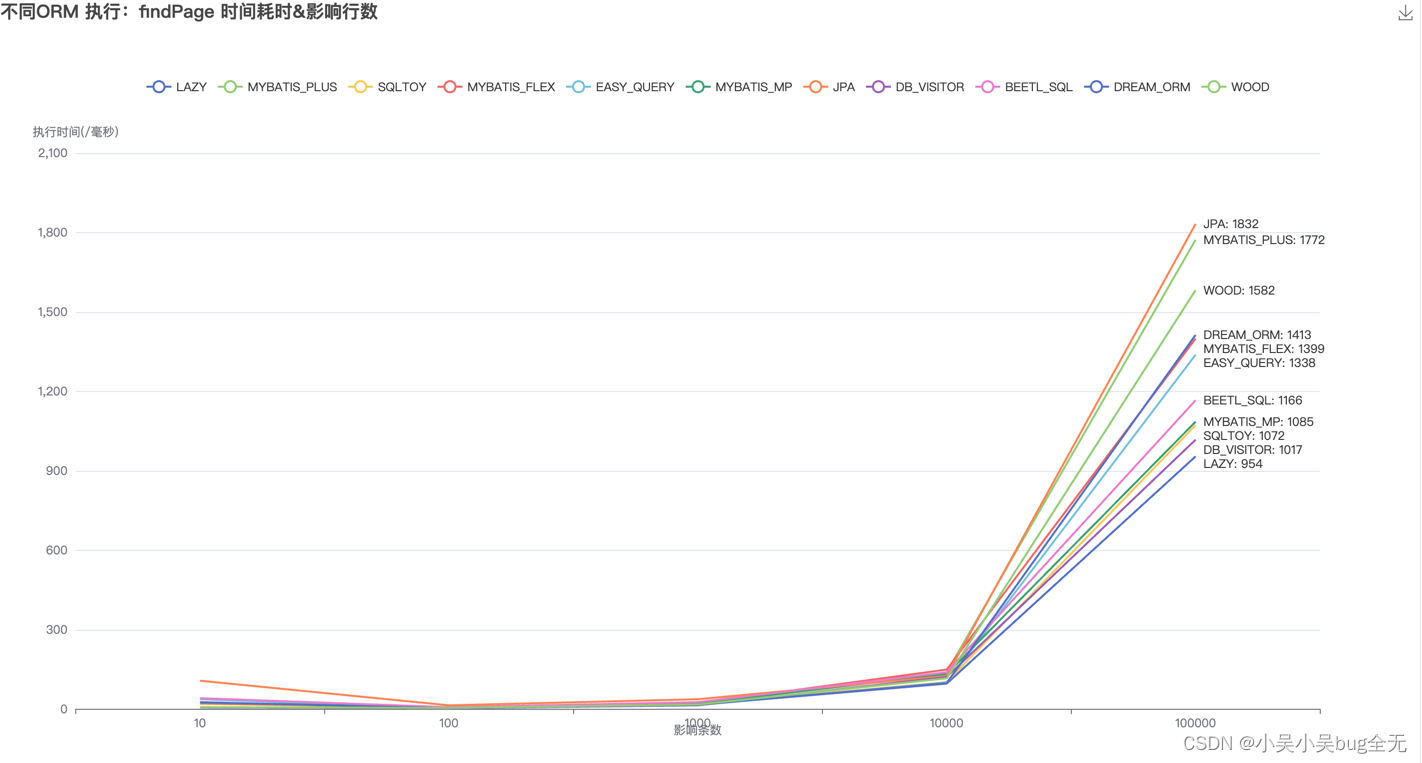
当我们在ES中使用关键字搜索文档时,会得到由from+size指定的窗口大小多个文档,这些文档按照max_score的大小从高到低排列。毫无疑问,max_score衡量了查询结果和关键字之间的相似度或者说相关度大小,那么你是否好奇过它是如何计算出来的,本篇博文就来谈谈max_score的计算过程。
max_score如何计算
tf-idf公式
自然语言处理有一个计算文档权重的tf-idf公式(tf*idf),max_score的计算,也主要使用该公式。其中TF词频(Term Frequency)指的是词条t在文档中出现的频率,IDF逆向文件频率(Inverse Document Frequency)指的是包含词条t的文档总数/全部文档总数的倒数取对数(逆向的意思就是取倒数,即全部文档总数/包含词条t的文档总数)。
tf不难理解,同一个文档中出现频率越高的词重要程度越高,idf是为了排除同时在多个文档出现的高频词,比如定冠词the、a的在同一个文档中词频很高,且在多个文档中出现,但是并没有什么实际意义,因而取倒数作为一种重要性上的惩罚。
tf-idf公式的核心思想是:如果某个词条在一篇文章中出现的频率TF很高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
max_score计算公式
max_score计算公式如下,max_score
=
b
o
o
s
t
∗
t
f
∗
i
d
f
=boost * tf * idf
=boost∗tf∗idf,其中tf和idf的计算稍有不同,下文有详细说明,boost可以手动指定,用来控制查询词条的权重。
| 参数 | 含义 | 取值示例 |
|---|---|---|
| boost | 词条权重 | 2.2(基础值)* 当前字段查询权重(默认为1,可以手动指定) |
| tf | 词频 | 0.66753393 |
| idf | 逆文档频率 | 6.2964954 |
| max_score | 得分 | 9.246874 = 2.2 × 1 × 0.66753393 × 6.2964954 9.246874 = 2.2\times1 \times 0.66753393\times6.2964954 9.246874=2.2×1×0.66753393×6.2964954 |
在search时,通过指定参数explain=true,即可在返回的_explanation字段内看到max_score的计算过程和中间结果:
GET /test_index/_search?explain=true
{
"query": {
"match": {
"test_field": "测试用query"
}
}
}
上述示例查询结果如下:
{
... # 省略其他字段
"_explanation" : {
"value" : 9.246874,
"description" : "sum of:",
"details" : [
{
"value" : 9.246874,
"description" : "weight(test_field:升级 in 398) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 9.246874,
"description" : "score(freq=1.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 6.2964954,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 1,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 813,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.66753393,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 2.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 9.088561,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
]
}
}
下面我们来仔细研究一下这里面的每一项。
计算tf
tf(Term Frequency,词频):搜索文本分词后各个词条(term)在被查询文档的相应字段中出现的频率,频率越大,相关性越高,得分就越高。
{
"value" : 0.66753393,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 2.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 9.088561,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
t f = f r e q f r e q + k 1 × ( 1 − b ) + b × d l a v g d l tf=\frac{freq}{freq+k1\times(1-b)+b\times \frac{dl}{avgdl}} tf=freq+k1×(1−b)+b×avgdldlfreq
| 参数 | 含义 | 示例取值 |
|---|---|---|
| freq | 文档中词条出现的次数 | 1.0 |
| k1 | 词条饱和参数 | 1.2(默认值) |
| b | 长度规格化参数(平衡词条长度对于整个文档的影响程度) | 0.75(默认值) |
| dl | 搜索的关键词在当前文档中的分解字段长度 | 2.0 |
| avgdl | 查询出来的所有文档被字段分解长度总和/查询文档总数 | 9.088561 |
可以理解为自然语言处理中的tf做了一定程度的正则化。
计算idf
idf(Inverse Document Frequency,逆文档频率):搜索文本中分词后各个词条(term)在整个索引的所有文档中出现的频率倒数,频率越大,频率倒数越小,相关性越低,得分就越低。
{
"value" : 6.2964954,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 1,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 813,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
}
i d f = l o g ( 1 + ( N − n + 0.5 ) n + 0.5 ) idf=log(\frac{1+(N-n+0.5)}{n+0.5}) idf=log(n+0.51+(N−n+0.5))
| 参数 | 含义 | 示例取值 |
|---|---|---|
| n | 包含查询词条的文档总数 | 1 |
| N | 包含查询字段的文档总数 | 813 |
同样也可以理解为自然语言处理中的idf做了一定程度的正则化。
boost查询权重
boost在同一个字段匹配多个词条时才有实际意义,它用来控制每个词条的计算相关度的权重。
示例查询:
GET /test_index/_search?explain=true
{
"query": {
"bool": {
"should": [{
"match": {
"test_field": {
"query": "xxx",
"boost": 1
}
}
},
{
"match": {
"test_field": {
"query": "yyy",
"boost": 2
}
}
},
{
"match": {
"test_field": {
"query": "zzz",
"boost": 3
}
}
}
]
}
}
}
在上面的搜索计算相关度时,文档命中词条xxx时指定boost=1计算max_score,命中命中词条yyy时指定boost=2计算max_score,命中词条zzz时指定boost=3计算max_score。
参考文献
- ES系列–打分机制